



I’m Mike O’Neill and I’m a data nerd who uses Azure Data Explorer, or Kusto, every day to glean insights into Azure’s developer and code-to-customers operations.
I’ve worked in data-driven organizations for most of the last decade plus, so it’s been a bit of a culture shock to work in an organization that doesn’t have data and analytics in its DNA.
I knew coming in that my team in Azure didn’t have the foundation of a data-driven culture: a single source of truth for their business. That was my job, but I naively expected this to be purely a technical challenge, of bringing together dozens of different data sources form a new data lake.
I learned very quickly that people are the bigger challenge. About a year into the role, my engineering and program management Directors both hired two principal resources to lead the data team. I was excited, but the three of us were constantly talking past each other, and now I think I know why.
I was working to build a single source of truth so that many people, including our team, could deliver data insights, but those new resources focused on us delivering data insights.
The difference is subtle, I realize, but it’s a big deal: if we only deliver data insights, we’ll end up as consultants, delivering reports to various teams on what they need. That’s work for hire, and it doesn’t scale.
If we build a single source of truth, those various teams will be able to self-serve and build the reports that matter to them. Democratizing data like that is a key attribute of a data-driven culture.
So why were the three of us talking past each other when we were talking about same business problems? I think it was a matter of perspective and experience.
To oversimplify the data space, I think there are four main people functions, and the experience learned from each function guides how people view the space. Our v-team had people from all of those spaces, and the assumptions we brought to the conversation were why we were speaking past each other.
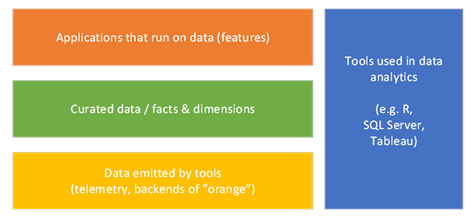
First is this orange box, which is about doing, well, useful stuff with data. This is what everybody wants. This is where data scientists and analysts make their money.
The risk with this box is an overfocus on single-purpose business value. It’s great to have a useful report, but people who live only in this box don’t focus re-usable assets. Worst case scenario, it’s work-for-hire, where you shop your services from team to team to justify your existence.
Second is this yellow box, which represents telemetry. I’m using that word far more broadly than the dictionary defines it: to me, it’s the data exhaust of any computer system. But that exhaust is specific to its function and consumption is typically designed only for the engineers that built it.
The risk here is around resistance to data democratization. If you’re accustomed to no one accessing the data from your system, you won’t invest the time to make it understandable by others. When you do share the data, those new users can drown you in questions. Do that a few times, and you learn to tightly control sharing, perhaps building narrowly scoped, single-purpose API calls for each scenario.
Third, you need tools to make sense of the data: this is the blue box in my diagram. There’s a bajillion dollars in this space, ranging from visualization tools such as PowerBI and Tableau, to data platforms such as Azure Data Lake, AWS Redshift and Oracle Database. The people in this space market products to the people in my orange box, whether it’s data scientists or UI designers.
The risk in the blue box is in the difference between providing a feature relevant to data and delivering data as a feature. It’s easy to approach gap analysis by talking to teams about what data their services emit and taking at face value they’re assessment of what their data describes.
If you are in the data warehouse space, however, a gap analysis is about the data itself, not in the tools used to analyze that data. Hata gaps tend to be much more ephemeral than gaps in data product features, especially when you are evaluating a brand-new data source. In my experience, a conversation is just a starting point. You can trust, but you need to verify by digging deeply into the data.
And that brings me to the green box. In current terminology, that’s a data lake, and it’s where I’ve lived for the past decade. The green box is all about using tools from the blue box to normalize and democratize data from a plethora of telemetry sources from the yellow box, such that people in the orange box can do their jobs more easily. It’s about having a single source of truth that just about anyone can access, and that’s one of the foundations of a data-driven culture.
So what’s the risk in the green box? I like to say that data engineers spend 90% of their time on 1% of the data. Picking that 1% is not easy, and perfecting data can be a huge waste of money. Data engineering teams are very, very good at cleaning up data, and they are also very, very good at ignoring the law of diminishing returns. But they are not very good at identifying moral hazards, at forcing upstream telemetry sources to clean up their act.