



One of the challenges I face is handling outliers in the data emitted by the engineering pipeline tools that thousands of Azure developers use. For example, our tools all have queues, and a top priority is that queue times are brief.
This is the shape of data you’d expect to see for a queue. A quick peak after a few seconds, and then this long tail.
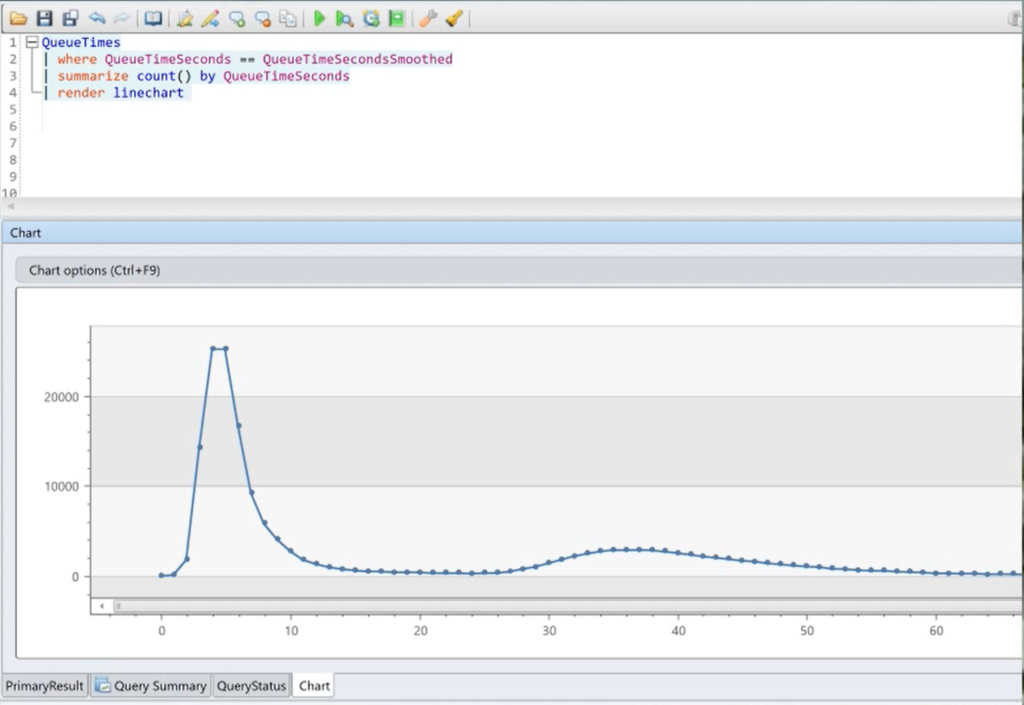
But that’s not what our actual distribution of queue times looks like. The long tail is so long, it looks like a right angle.
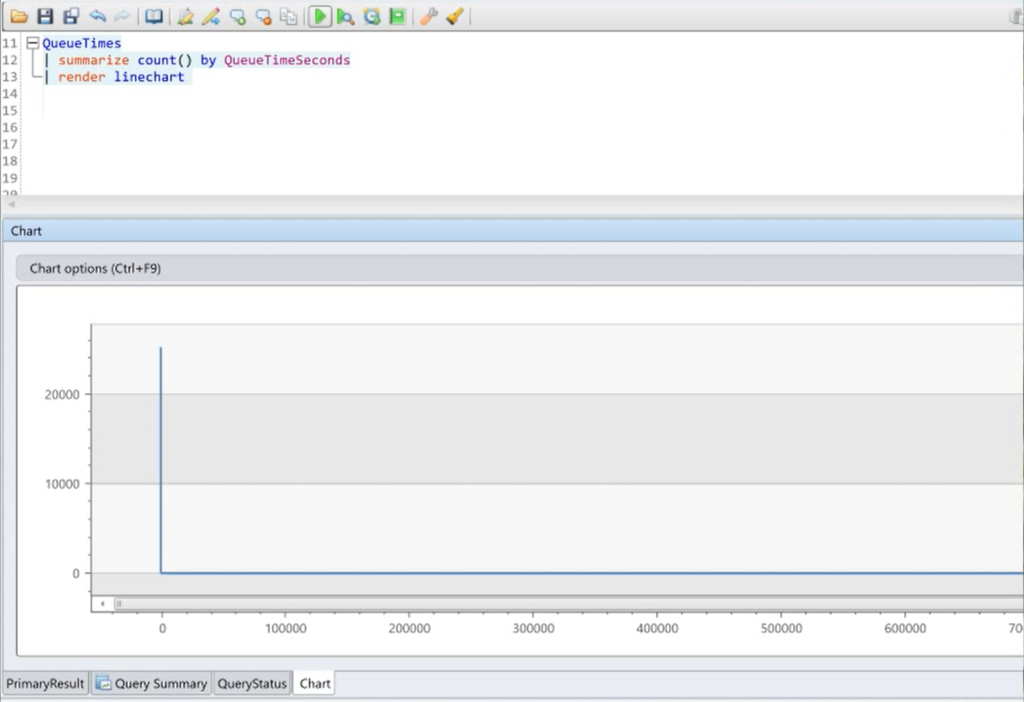
So what’s happening? Well, the mean queue time is 197 seconds, but if I remove the outliers, it’s just 18 seconds. Why the huge difference in averages? My max queue time is almost ten days, but when I exclude outliers, the max is just 81 seconds.
Six percent of my queue time values are outliers, ranging from minutes to days. I asked the team that manages this tool, and several things could be happening, from teams pausing a job while it’s in the queue, to misconfigurations by users. In short, none of these values represent valid queue times.
So how do I exclude those extreme values? I could pick an arbitrary line: everyone here in Azure loves the 95th percentile, because everyone remembers that’s two standard deviations from the mean in a Normal distribution. The problem is that the 95th percentile isn’t relevant for this type of distribution: it’s just luck that in this case, the 95th percentile is 106 seconds. It could just as easily be thirty minutes.
The better way to do this is to identify outliers based on the data. In fact, that’s the definition of an outlier: a data point that differs significantly from other observations. One common method of doing is called Tukey’s fences. I don’t have a Ph.D. in statistics, so I’m not going to explain how it works. In fact, that’s not what this channel. It’s about showing how to do powerful things in Kusto without a lot of effort, and Kusto’s series_outliers operator is just that.
Here’s how you do it.

Step 1: pack all the QueueTime values into a list using the make_list operator.
Step 2: feed that list into the series_outliers operator.
Step 3: unpack it all with mv-expand.
Step 4: is the one bit that Kusto doesn’t do automatically for you. The values in the Outliers column aren’t self-explanatory, but they represent how far the measurement is from the bulk of your data. Anything greater than 1.5 or less than -1.5 is an outlier, and beyond plus-minus three, the values are really, really out there.
You can’t have negative queue time, so I just look at values below 1.5 and I’m set.